Disclaimer: I am not a financial expert. I am a student in statistics and probability. What follows is some exposition on an exercise found in one of my textbooks. It was not a trading book, but rather a book on actuarial models for insurance. I thought it was interesting, and decided to write about it.
I.
On finance.yahoo.com, stock price data can be easily downloaded and analyzed. Here, we consider a stock and a cryptocurrency, Google and Bitcoin, which are words that have passed through the lips of pretty much every person who knows what an investment is. Bitcoin, in particular, was the source of many a meme, when the lovable cryptocurrency topped out in value at $19345.49. Google, on the other hand, is an actual company, with investors and products, and likely was what you used in order to find this blog. Now, if you had some fixed 
II.
From finance.yahoo, we consider historical stock price data from 2017-05-05 to 2018-05-05 (essentially present day, at the time of this writing). In this case, we will look at the Close price. Here is the time series of the Bitcoin closing price (366 observations):
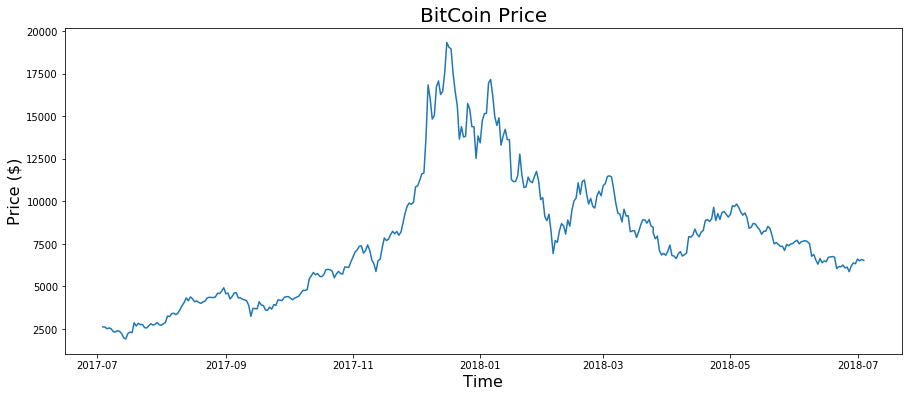
And we also have the Google price data (255 observations – some days are missing in the data because of holidays, or an error on the part of finance.yahoo. Ideally, we would want to have data with the same number of observations, but since this isn’t a “serious” exercise, we can say that this is good enough).

We can see that clearly both Bitcoin and Google saw big increases in price around the start of 2018, but the closing prices for bitcoin appear to be dropping as 2018 continues on, yet Google has remained relatively high. Because stock prices are effectively stochastic, ie, random, we really cannot draw any conclusions based on these charts alone. Though, some speculate that bitcoin prices are going to take off again at some point (“To the moon!”). If all I knew were these charts, it would be difficult to discern which asset will make you more money. Though, perhaps I would be tempted to go bitcoin, as its apparently high volatility may indicate another large spike in price in the future. In fact, what can we say about the returns of these two assets?
A return is defined as the formula every business major knows: 


So it follows that when 

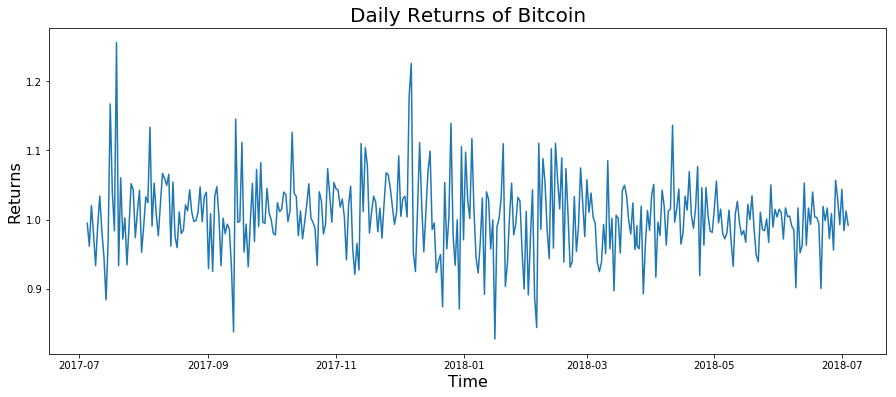

The graphs of the daily returns from both assets appear to resemble white noise, which is indicative that the returns are approximately normally distributed. (A lie. Keep going). This is actually a key assumption in proceeding with our analysis, so it is pertinent to take a glance at the quantile-quantile plots as well:
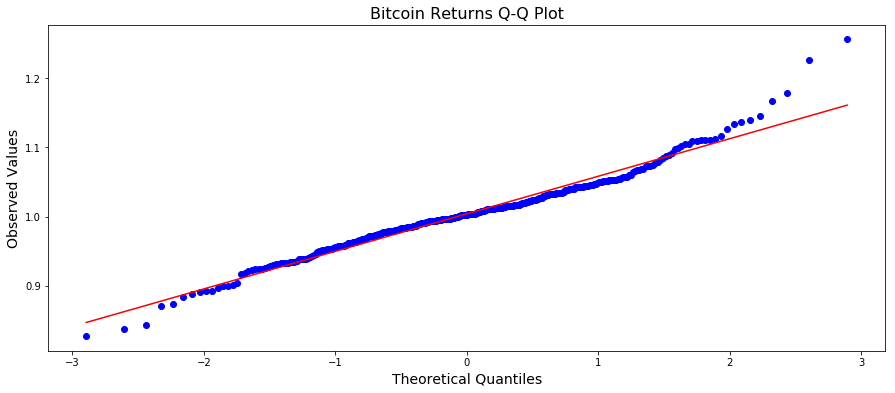
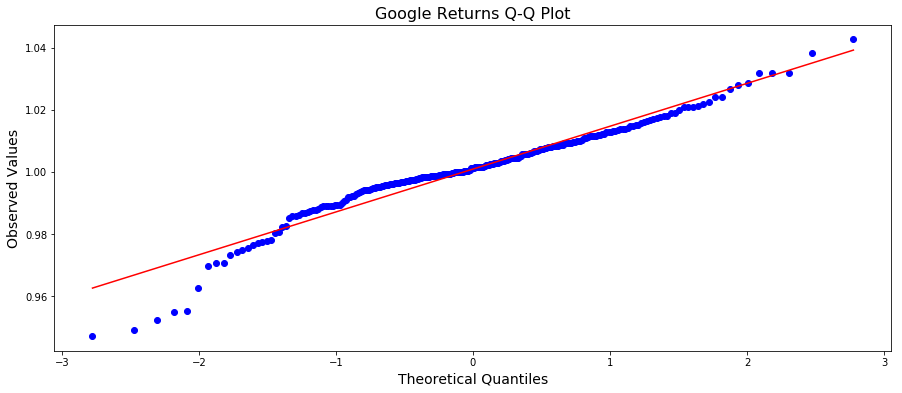
Both data sets are probably close enough. There is a bit of fuzziness in the tails here, and some skewness (in particular, Google has some right tail skew), but it’s not totally unreasonable to assume that the data are approximately normally distributed.
(NB: We are fibbing a bit. Because the definition of returns we are using is simply a ratio, they are actually not normally distributed, as the return is strictly greater than zero. In The Black Swan, Nassim Nicholas Taleb argues heavily against the profilic use of assuming the normal distribution in the financial sector – and for good reason. Bad assumptions on models can be disasterous and it’s a generally unwaranted assumption, for actual return data has fatter tails than a normal distribution. However, since it is better to beg for forgiveness rather than permission, we will take our returns data as approximately normal, and continue with the exercise. Our aim here is to explore the concept of risk and utility; not to argue about the distribution of returns.)
It’s a relatively common assumption to assume that the daily returns are a stochastic variable, and so we can let 


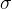




On inspection, it appears that the Bitcoin asset gives a higher average return than the Google asset, however, it suffers from a higher standard deviation, which is indicative of more volatility – you are more likely to get larger spikes of gains, as well as larger spikes of losses. Perhaps this is to be expected.
III.
(NB: The following conversation may be skipped for those who are well acquainted with VaR and its concepts.)
The Value-at-Risk (VaR) criterion is, as defined in Rotar’s Actuarial Models: The Mathematics of Insurance is the “smallest value 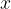



This is a definition of the 
This can also be said to be the value at 



We can also place this VaR on a distribution of losses, where the random variable 
Since we can choose 
We say that we prefer 


Now for the relevant part. From Actuarial Models: Suppose we have a normally distributed random variable 





Since multiplying a normally distributed random variable by a constant results in a normally distributed random variable, this means we can actually compute the value at risk in our investments in Bitcoin and Google assets, as the daily returns are (approximately) normally distributed. If we think of the amount of money we invested as a weight or scalar (say n dollars), we can define a new random variable 

![E[X^*] = nE[X] = n\mu](https://s0.wp.com/latex.php?latex=E%5BX%5E%2A%5D+%3D+nE%5BX%5D+%3D+n%5Cmu%C2%A0&bg=ffffff&fg=000000&s=1&c=20201002)


Since we are generally interested in small probabilities (as we are primarily interested in this notion of risk), we will take 


IV.
By the preceding discussion, we can suppose that we are willing to invest n dollars into either Bitcoin or Google. We will assume that the better choice of investment will be the asset that has a smaller risk. Under the VaR criterion, we want to see which asset will not only make us the most money, but has the smallest penalty should something bad happen – like an unexpected drop in prices. Since this is based on our definition of return as a ratio, the absolutely value in the price shouldn’t matter from a mathematical point of view.
Define 


![q_\gamma(X^*) = nE[X] + n q_{\gamma s}SD(X) = n(1.0040) - n1.96(0.0547)](https://s0.wp.com/latex.php?latex=q_%5Cgamma%28X%5E%2A%29+%3D+nE%5BX%5D+%2B+n+q_%7B%5Cgamma+s%7DSD%28X%29+%3D+n%281.0040%29+-+n1.96%280.0547%29+&bg=ffffff&fg=000000&s=1&c=20201002)
![q_\gamma(Y^*) = nE[Y] + n q_{\gamma s}SD(Y) = n(1.0009) - n1.96(0.0140)](https://s0.wp.com/latex.php?latex=q_%5Cgamma%28Y%5E%2A%29+%3D+nE%5BY%5D+%2B+n+q_%7B%5Cgamma+s%7DSD%28Y%29+%3D+n%281.0009%29+-+n1.96%280.0140%29+&bg=ffffff&fg=000000&s=1&c=20201002)
We now have a function of our investment n which we can plot in Python:
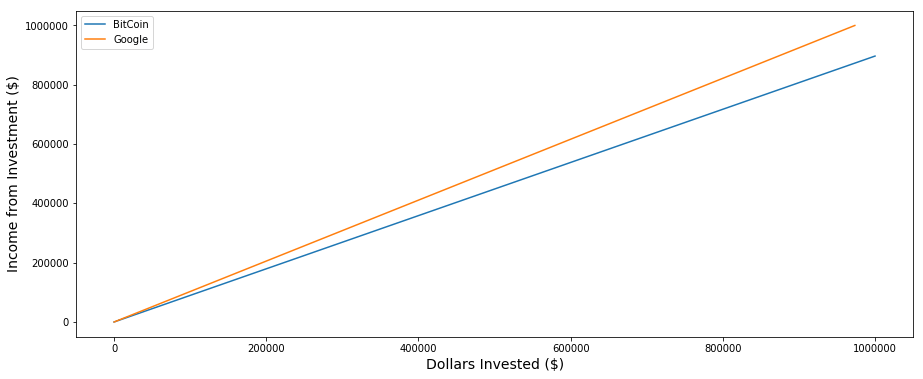
We can see that the more money we invest at a time, the larger the VaR for the Google asset. As a concrete example, if we compare an investment of $10,000 in Google and Bitcoin, then our value at 2.5% risk for both assets is


By definition of VaR, this means that 2.5% of the time, we stand to lose $1,032.12 dollars on Bitcoin, but only $265.4 dollars on Google. Bitcoin is a riskier bet. This is intuitively obvious just from looking at the larger standard deviation. The investor is in a position to lose (or gain) much more money than in a bet with a higher variance. Based on this analysis, it seems that the choice of investment should be in the Google asset. Since 
But is this result generalizable to all humans? Should every investor make this choice? Perhaps, but we know that human beings are not always rational, but nevertheless their behavior can sometimes be modeled as maximizing some kind of utility function. I don’t know what my utility function is, but for whatever reason, the utility out of typing up this blog post is higher than the utility I get from doing homework.
V.
Utility functions are, in essence, some way of characterizing human behavior. Human beings all want something, and that something is often fairly intangible. Yet, one utility that seems “modelable” is the utility of money. Money gives us utility almost however you define it, since money can serve as a proxy for the things we actually want — be it power, sex, or even a new video game. (I may not value money at all as an axiom, but if I value playing video games, then I value free time so that I can play video games, and also the money required to purchase them. Ergo, I have a job that gives me weekends off. This property of valuation seems to hold almost everywhere in adults that like video games, except on the set of video-game pirating NEETs, e.g., 4channers, which is a set of small measure.)
If we take it as an axiom that every human has some innate, unknown utility function, and that human beings are, in general, utility maximizers, then we can use some relatively simple mathematics to model a person’s behavior. There are caveats. One can never assume that a model is true, as true behavior (of anything) is inherently unknowable (empiricism helps, but only serves to make models more accurate. Not more true).
Here we denote a utility function by u. A classical example of a utility function is the natural logarithm 

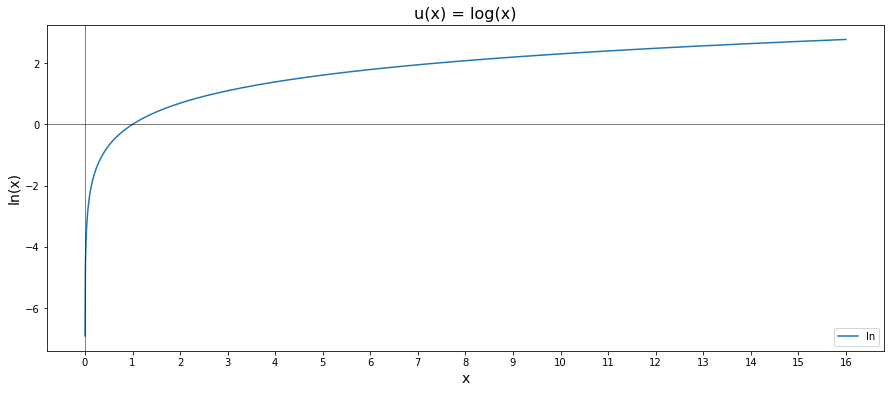
The expected utility maximization criterion is an axiom that if someone is a utility maximizer, then they would prefer an investment strategy
![X \succeq Y \iff E[u(X)] \geq E[u(Y)]](https://s0.wp.com/latex.php?latex=X+%5Csucceq+Y+%5Ciff+E%5Bu%28X%29%5D+%5Cgeq+E%5Bu%28Y%29%5D%C2%A0&bg=ffffff&fg=000000&s=1&c=20201002)
Perhaps the simplest utility function is simply dollar amounts, but it doesn’t capture the inherent decision making process used by actual humans. How people characterize their investments has a lot to do with how the feel about them, and their expected return, and the potential risks involved in some strategy. That’s where a utility function comes in — it is an attempt to capture some of those decision making processes.
We will avoid some details here, but essentially investors (or gamblers) can be described as either being risk averse, risk taking, or risk neutral. An investor who is risk averse is an investor who, naturally, prefers stability from their assets. Since the VaR for the Google asset is higher than the VaR for Bitcoin, a risk averse investor would be more inclined to invest in Google over Bitcoin. However, Bitcoin, has a larger variance, and so there is a probability of a large spike in price – and that means someone is potentially makes a lot of money. An investor who still prefers Bitcoin despite the lower VaR could be said to be a risk-taker. He or she is willing to invest the money and take the risk of losing it for the (likely small) probability of a large pay off.
Utility functions don’t have to be positive (note that the natural log is not strictly postive). And since we only care about maximizing our “utils”, we can actually use the natural logarithm to model investment strategy behavior in a “rational” human being. As 

But on the other hand, since the natural logarithm diverges to 
Passing the return data from both Bitcoin and Google and taking a mean gives an expected “utility” of 0.0025 for Bitcoin and 0.0008 for Google – in this scenario, we actually prefer to invest in Bitcoin.
(This procedure may seem ad-hoc, but has some justification. Let 

![\frac{u(X_1) + u(X_2) + ... + u(X_n)}{n} \approx E[u(X)]](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bu%28X_1%29+%2B+u%28X_2%29+%2B+...+%2B+u%28X_n%29%7D%7Bn%7D+%5Capprox+E%5Bu%28X%29%5D%C2%A0&bg=ffffff&fg=000000&s=1&c=20201002)
by the law of large numbers when n is large. )
What about a different utility function? Consider the utility function 
![Var(X) = E[X^2] - E[X]^2](https://s0.wp.com/latex.php?latex=Var%28X%29+%3D+E%5BX%5E2%5D+-+E%5BX%5D%5E2+&bg=ffffff&fg=000000&s=1&c=20201002)
![E[X^2] = Var(X) + E[X]^2](https://s0.wp.com/latex.php?latex=E%5BX%5E2%5D+%3D+Var%28X%29+%2B+E%5BX%5D%5E2%C2%A0&bg=ffffff&fg=000000&s=1&c=20201002)
![E[u(X)] = E[2aX - X^2] = 2aE[X] - E[X^2] = 2aE[X] -(Var(X) + E[X]^2)](https://s0.wp.com/latex.php?latex=E%5Bu%28X%29%5D+%3D+E%5B2aX+-+X%5E2%5D+%3D+2aE%5BX%5D+-+E%5BX%5E2%5D+%3D+2aE%5BX%5D+-%28Var%28X%29+%2B+E%5BX%5D%5E2%29&bg=ffffff&fg=000000&s=0&c=20201002)
And this simply becomes 





![E[u(X)] \approx 1.4989](https://s0.wp.com/latex.php?latex=E%5Bu%28X%29%5D+%5Capprox%C2%A01.4989+&bg=ffffff&fg=000000&s=1&c=20201002)
![E[u(Y)] \approx 1.5003](https://s0.wp.com/latex.php?latex=E%5Bu%28Y%29%5D+%5Capprox+1.5003+&bg=ffffff&fg=000000&s=1&c=20201002)
So our expected utility is now slightly higher for the Google strategy, which matches our intuition from the VaR criterion. (However, the difference between the two is extremely small, and increasing a results in us preferring Bitcoin again. Utility seems to be quite finicky).
VI.
So, which is it? Google or Bitcoin. I’m sorry to have to give a non-answer, but the non-answer is that it depends on your utility function. If you decide that the VaR criterion is “good enough” to decide on which to invest in, then perhaps you’re very risk averse, your utility function is concave. In that case, Google seems like a safe bet. Even safer – a mutual fund. If, however, you’re willing to shoulder the risk of losing everything at the prospect of big gains, then obviously bitcoin is the answer here, as it has been for many other individuals. However, modeling risk seems like a general good idea. It’s why traders seem to espouse having diversified portfolios (there is a very simple mathematical proof for why this reduces variance, and thus risk, of your investments. But even heuristic reasoning may suffice. If all your eggs are in one basket, and that basket gets hit with a financial nuclear bomb, then you lose all your eggs. If you have many baskets, and one egg in each, then losing one basket means you only lost one egg — that is, one investment.)
****
Caveats and further questions:
i) As expressed earlier, the distribution of returns is mostly not normal. It is a very strong and simplifying assumption, which is why it is done, but by assuming the distribution of returns is normal, and then calculating the VaR at a particular percentage analytically, the actual chance of the risky event occurring is higher – perhaps much higher. There are non-parametric methods that exist, which make no assumptions about a distribution and work entirely on historical data. This is called historical simulation. There is another method that uses Monte Carlo methods, but I don’t know much about that, yet. These methods are likely more robust, in that they use less assumptions.
ii) Utility functions as a means to optimize a portfolio seem weird to me. A utility function is a function that essentially describes the behavior of an individual by attaching “utils” to some notion of having more or less of something. This criteria for portfolio optimization is used, indeed, but I don’t know enough about it to really comment deeply. Maybe another time.
iii) There is a critical error of VaR in which Taleb occasionally critiques. When you fix a probability level, say 1%, and then calculate VaR, you make the very explicit assumption that events with probability less than 1% do not occur. This is perhaps certifiable madness in finance. If you take the stock market as entirely stochastic, which many people do thanks to the Efficient Market Hypothesis, then the stock price movements are a random walk. Since a random walk does not depend on the past at all, and markets are here to stay, eventually a “rare event”, one that occurs with probably less than 1% is bound to happen, for someone, somewhere. And here’s the problem – value at risk assumes that it doesn’t. This may not be a big deal, but there isnt’ evidence that risk and expected losses at a particular risk level are linear. In fact, as Taleb argues, it is these rare events, these Black Swans that are most impactful, most disastrous. It’s possible that while you can manage the loss of a 1% event, a 0.5% event could liquidate your company. That said, all is not lost for VaR. Part of managing risk is having a “risk measure”, in which multiple risk criterion are considered and given relative weights dependent on the concerns of the individual or the firm. There is, also, Conditional VaR, or “expected shortfall” which tries to estimate the impact of extremely rare events. Moreover, there are many other risk criterion than those two, enough to fill a textbook on the subject.
iv) I am not a trader, but I am curious about a trading strategy for the individual: I believe that one could come up with a coherent risk measure that appeals to them, and simply evaluate many stocks on that risk measure, and then pick the stocks based on obtaining the smallest amount of risk, with some ratio of highest expected returns. This is a thing for portfolio management in the investment industry in which there are ample resources (google “risk parity”), but I wonder if it could be specified into a coherent strategy for the individual with regular-person level resources. I am likely missing something here, as this seems obvious to me, but I am not a trader and thus have not read any trading books. It’s possible that this is a strategy considered in chapter 1 of some book somewhere, but I also get the feeling that this method would be too computationally intensive for the general public, but would appeal to the analytically minded. If anyone knows, let me know. I might try and explore this idea.
v) The data at the time of this writing is already outdated. I figure that is probably just okay.
vi) Future project: investigate the Efficient Market Hypothesis by trying some machine learning techniques on stock data. Does the past model the future? Economists say no, but economists also failed to predict the 2008 crash, and the Efficient Market Hypothesis precludes the idea of a bubble and the event of a crash, so definitely worth looking into. In fact, Bitcoin has been used as an a counterexample to the EMH. Since the EMH is a mathematical derivation that relies on a mathematical assumption, precisely one counterexample is enough to refute it.
